The MBROLA synthesiser is controlled by means of command files. These files
contain the following information:
* phonetic transcription, using phonemes and allophones
* durations of phonemes and allophones
* pitch points, i.e. turning points in a stylised pitch contour
* optional: comment
Information about the 53 phoneme and allophone symbols for this Dutch database
is available in a separate table
(http://www-uilots.let.uu.nl/~Hugo.Quene/onderwijs/lotsummer98/nl2.txt). This is
an example of a command file for the Dutch utterance Hallo!:
; Utterance: "Hallo!"
_ 100 100 120
h 96
A 48
l 76 5 100 75 120
o 224 25 85
_ 100 40 70
The first line is comment. Comment lines start with a semicolon (;). The other
lines contain the following information:
* 1st column: phoneme or allophone segment. The "underscore" represents silence;
each utterance begins and ends with a silence symbol.
* 2nd column: duration of the segment. The utterance starts with a silence of
100 ms duration. The initial [h] has a duration of 96 ms, [A] lasts 48 ms, etc.
* remainder: zero or more pitch points. Each pitch point is indicated by two
numbers. The first number of the pair indicates the position, in time, expressed
as a percentage of the segmental duration. The second number of the pair
indicates the pitch in Hz.
More about diphones
Diphones are short fragments of speech, recorded and processed. When you are
synthesising an utterance, the appropriate diphones are taken from the database,
concatenated, given the requested duration and intonation (using a PSOLA-like
procedure), and con verted to sound.
Hence, end users of the synthesizer have no control over the degree of
assimilation in the output speech. We have to wait and hear to what extent the
original speaker of the database has applied coarticulation or assimilation in
the speech fragments. We c an, however, request certain phonemes in the phonetic
transcription, thus forcing the synthesizer to 'complete' assimilation.
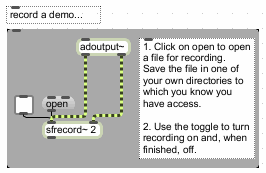
1. A bad example
Copy the command file zoutzuur.pho to your diphone directory, and synthesise
this file with the command dsyn zoutzuur. What is wrong with it? Inspect the
command file, with a text editor or with the Unix command cat zoutzuur.pho.
2. You can do better
Open the command file zoutzuur.pho in a text editor. [*] Adjust the durations of
the critical VCCV segments. Save the file, and synthesize it again. Do both
realisations sound perfect to your ears? If not, go back to the point marked [*]
above. W hat is the ratio between C and V2 durations, in both realisations? What
is the sum of their durations?
3. Now on your own
Using the now perfect file zoutzuur.pho as an example (e.g. for the pitch
contour), your task is now to make synthetic versions of all utterances which
were measured in session 2.
Make versions both with (complete) assimilation, and without assimilation. (Use
the phoneme table to determine the appropriate transcription symbols). Do this
for corresponding 'viable' and 'unviable' cases.
Compare the synthetic versions with the natural ones. You can even specify the
'natural' segment durations in the command files. How does that affect the
perceived segmentation?
Last updated on June 24, 1998, by Hugo Quen.
|